3
THE MOLECULAR BASIS OF GENETICS
OBJECTIVES:
By the end of this session the student should be able to:
* Outline the molecular
structure of DNA and RNA
*
Explain the significance
of specific base pairing
*
Define the main
properties of DNA
*
Work out the
sequence on m-RNA from that on the coding and transcribed strands of DNA
*
Define
transcription and translation and state where they occur
*
Distinguish between single- stranded and
double-stranded nucleic acids
*
Explain the
meaning of denaturation and re-annealing of DNA
NUCLEOTIDES
The
molecules of Deoxyribose Nucleic Acid (DNA) and Ribose Nucleic Acid (RNA) are common to all living organisms and form the basis of life. Both molecules consist of long chains of nucleotides.
A nucleotide consists of three main components (Fig 3.1):
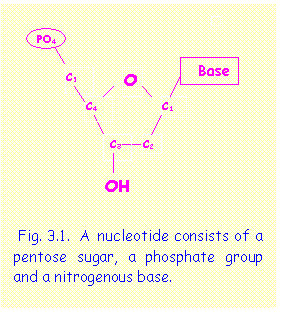 a)
a pentose sugar
consisting of a five-sided ring containing 5 carbon atoms, numbered clockwise
from 1 to 5. This sugar is ribose in
RNA or deoxyribose in DNA,
a)
a pentose sugar
consisting of a five-sided ring containing 5 carbon atoms, numbered clockwise
from 1 to 5. This sugar is ribose in
RNA or deoxyribose in DNA,
b) a phosphate group (PO4--) attached to C5 of the pentose ring.
c) a nitrogenous base attached to C1 of the pentose ring. The bases present in DNA are Adenine (A), Guanine (G), Cytosine (C), and Thymine (T). In RNA Uracil (U) replaces Thymine.
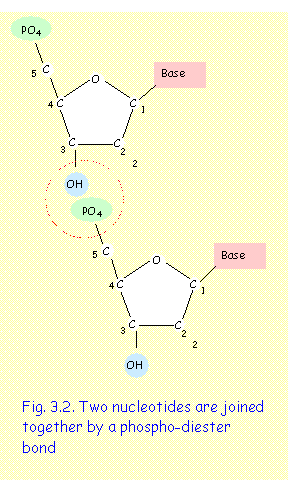 A nucleoside consists of a ribose sugar with an
attached base. Addition of a phosphate
group to the nucleoside forms a nucleotide. Thus there are five nucleotides
that form the building blocks of DNA and RNA - Adenine, guanine, cytosine,
thymine and uracil nucleotides.
A nucleoside consists of a ribose sugar with an
attached base. Addition of a phosphate
group to the nucleoside forms a nucleotide. Thus there are five nucleotides
that form the building blocks of DNA and RNA - Adenine, guanine, cytosine,
thymine and uracil nucleotides.
A hydroxyl group (OH), situated at C3 of the pentose ring, is the reactive site where one nucleotide interacts with the phosphate group of another nucleotide to form phosphodiester bond (fig. 3.2).
Di-nucleotides and tri-nucleotides consist of two and three nucleotides respectively. Poly-nucleotides, such as DNA and RNA consists of long chains of nucleotides.
A polynucleotide chain has a distinct polarity. It has a PO4 group attached to the C5 at one end - this is termed the 5’ end; and an -OH group attached to C3 at the other end - this is termed the 3’ end. New nucleotides may be added to a nucleotide chain only at the 3’ end. Thus, increase in length of a nucleotide chain is always unidirectional and occurs only in the 5’ to 3’ direction
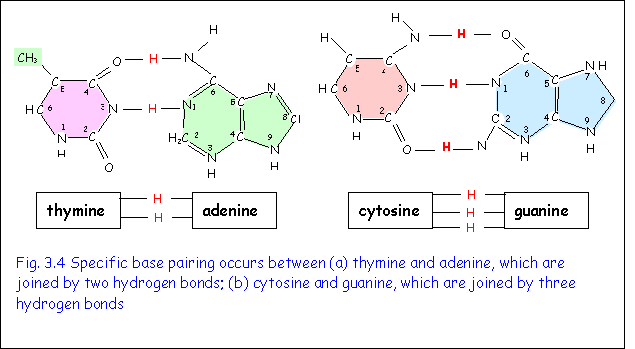
The bases present in DNA and RNA are divided into two groups (Fig3.3).
1. Adenine and guanine are purines and consist of two nitrogenous rings. They differ in the position of the amino group (NH2).
2. Cytosine, thymine and uracil are pyrimidines and consist of one nitrogenous ring. They differ in the nature and position of the side groups that are NH2 and CH3 respectively.

Specific base pairing occurs between nucleotides on opposite strands of DNA (Fig. 3.4). Thymine on one strand is always linked to adenine on the other strand by two hydrogen bonds. Cytosine on one strand is always linked to Guanine on the other strand by three hydrogen bonds. Specific base pairing is one of the most important features of DNA. It is crucial in the processes of DNA replication and transcription, which are two of the main functions of this molecule.
 DNA
DNA
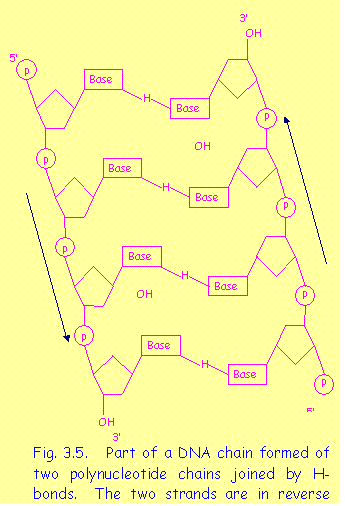
The DNA molecule consists of two very long nucleotide chains (or strands) arranged in the form of a double spiral with the following properties:
* the two strands are antiparallel i.e. the 5' end of one strand lies next to the 3' end of the complementary strand.
* the two strands are twisted in the form of a double spiral
*
the bases on one strand are linked to corresponding
bases on the other strand by hydrogen bonds
RNA
RNA is similar to DNA in that it consists of a polynucleotide chain, but differs from it in the following respects: (a) it consists of only one strand; (b) the pentose sugar is ribose; (c) uracil replaces thymine.
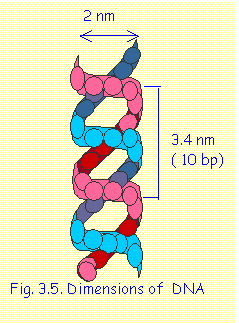
DIMENSIONS OF DNA
The double helical molecule of DNA has a diameter of 2 nanometers (nm). One spiral turn covers a length of 3.4 nm and contains 10 base pairs. (Fig. 3.5)
Note: 1 nm = 10-9m. (In old terminology, molecular dimensions were measured in Ǻngstrom Units (Ǻ) where 1 nm=10Ǻ.)
PROPERTIES OF DNA
The unique structure of the DNA
molecule explains its main properties and functions as the basis of life:
1. DNA REPLICATES ITSELF
 DNA replication is the
process by which a DNA molecule makes an exact copy or replica of itself (Fig.
3.6). The two strands forming the DNA molecule separate, and each strand then
serves as a template for synthesis of a complementary chain of
nucleotides. This function is possible
because of specific base
pairing. Adenine on one strand always pairs with Thymine on the other (A
- T), and Cytosine on one strand always
pairs with Guanine on the other (C - G). Specific base pairing ensures that the
sequence of bases is preserved on both daughter DNA molecules. DNA replication is the basis of propagation
of life.
DNA replication is the
process by which a DNA molecule makes an exact copy or replica of itself (Fig.
3.6). The two strands forming the DNA molecule separate, and each strand then
serves as a template for synthesis of a complementary chain of
nucleotides. This function is possible
because of specific base
pairing. Adenine on one strand always pairs with Thymine on the other (A
- T), and Cytosine on one strand always
pairs with Guanine on the other (C - G). Specific base pairing ensures that the
sequence of bases is preserved on both daughter DNA molecules. DNA replication is the basis of propagation
of life.
2. DNA CARRIES THE GENETIC
MESSAGE.
The sequence of bases on a stretch of a DNA forming a gene carries a coded message for a protein molecule. The complete DNA sequence of an organism is its genome, which contains all the genes coding for all the proteins present in that organism. The number of sequences contained in the genome varies according to the organism. The genome of a virus contains only a few thousand base pairs, forming the genes that code for a few proteins. More complex organisms have larger genomes and in man the genome contains 3 billion (3x109) base pairs. The size of the genome, however, is not proportional to the complexity of the organism. The sizes of the genomes of some organisms are shown in Table 3.1
|
Table 3.1. Sizes of genomes in a various organisms |
|
|
Organism |
Number of base pairs |
|
SV40 virus |
5,226 |
|
Escherichia coli, a bacterium |
4.1 x106 |
|
Salmonella typhimurium, a bacterium |
1.1x107 |
|
Saccharomyces cerevisiae, a yeast |
1.75x107 |
|
Zea mays (maize) |
6.6x109 |
|
Lilium longiflorum (lily) |
3x1011 |
|
Cyanorhabditis elegans,
a worm |
9x107 |
|
Drosophila melanogoster, the
fruit fly |
1.75 x 108 |
|
Mus musculus, the
mouse |
2.2 x 109 |
|
Homo sapiens, Man |
3 x 109 |
3. DNA CAN REPAIR ITSELF
When some bases on one strand of DNA are damaged or lost, the complementary
strand serves as a template for replacement of the damaged nucleotides ensuring
that the exact sequence is preserved.
This would be impossible with a single-stranded molecule. When the two strands of DNA become
separated, the complementary strands can find each other even in a complex
mixture of molecules. They can join up
once again by formation of hydrogen bonds.
This is possible because of the specific base pairing.
4. DNA IS
UNIVERSAL.
In all living organisms, whether bacteria, plants, animals or man, the structure of DNA is basically the same. Only the sequence of bases differs and consequently the genetic message. The resulting proteins and their specific functions are also different. However, because the basic structure of DNA is the same, DNA from one organism can be grafted on to the DNA of another organism. This is the basis of genetic engineering. DNA is the genetic material of prokaryotic and eukaryotic organisms but some viruses have RNA and others single-stranded DNA as their genetic material. However, the principles of replication and transcription remain the same.
The Genetic code
The genetic message is read in units of three bases, called codons. Each codon (triplet of bases) represents an amino acid. A chain of amino acids forms a specific polypeptide or protein, which is responsible for a particular function in a cell. Only one of the strands of DNA carries the genetic message. This is known as the template or transcribed strand because it forms the template from which the message is transcribed. The other strand is not transcribed and is known as the complementary or coding strand.
The template strand is transcribed to messenger RNA (m-RNA), which then itself acts as a template for the assembly of a polypeptide chain (Fig. 3.7) The template strand is read in the 3' to 5' direction while the m-RNA is synthesised in the 5' to 3' direction. The coding strand of DNA is never transcribed. Its sequence, however, happens to be the same as that on m-RNA (with the exception that T on DNA is replaced by U on RNA). This is why it is termed the "coding" strand. This nomenclature may be rather confusing and one should spend some time to ensure that the concept of complimentary sequences is understood.
TRANSCRIPTION AND TRANSLATION
This section explains how the coded message in DNA results in the synthesis of a specific protein. The process involves two main steps, namely transcription and translation. (Fig. 3.7)
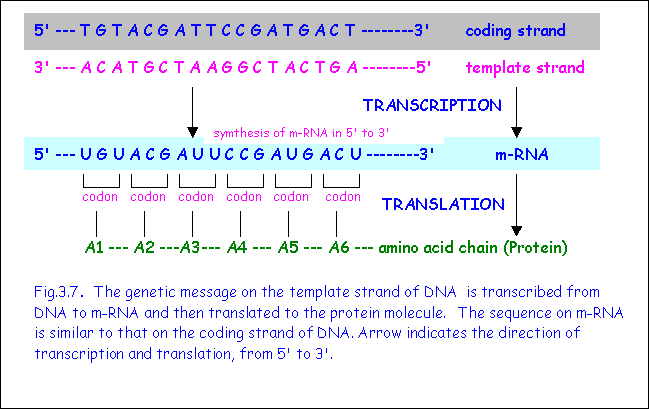 Transcription
Transcription
Transcription is the process in which the genetic message on the transcribed strand of DNA is copied on to m-RNA. The sequence of bases on DNA acts as a template for the synthesis of corresponding bases on m-RNA. Transcription proceeds in the 5’ to 3’ direction i.e. nucleotides are added at the 3’ end of the growing m-RNA. Note, however, that the coded message on DNA is read in the 3' to 5' direction. The enzyme RNA polymerase is necessary for this process, which occurs in the nucleus. The m-RNA moves out of the nucleus into the cytoplasm.
TRANSLATION
Translation
is the process in which the m-RNA attaches itself to the ribosomes and acts as
a template for the synthesis of a specific protein. The sequence of bases on m-RNA are read in triplets of bases
termed codons, which determine the sequence of amino acids forming the protein.
THREE TYPES OF RNA
The processes of transcription and translation involve three different types of RNA as intermediaries, each having different functions: messenger RNA (m-RNA), ribosomal RNA (r-RNA) and transfer RNA (t-RNA).
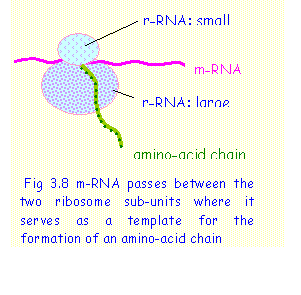 m-RNA
m-RNA
m-RNA is formed in the nucleus by transcription of a segment of DNA corresponding to a particular gene. The sequence of bases on m-RNA is complementary to that on the template strand of DNA and not a direct copy of it. m-RNA (representing a particular gene) detaches itself from the DNA and moves out from the nucleus into the cytoplasm. In the cytoplasm it attaches itself to a ribosome where it acts as a template for the synthesis of a protein (Fig. 3.8).
r-RNA
r-RNA is the main component of ribosomes, which also contain a number of associated proteins. Ribosomes are the sites of protein synthesis. There are four different r-RNAs. They all consist of single stranded RNA molecules coiled upon themselves.
 Ribosomes
consist of two sub-units, one large sub-unit and one small sub-unit (Fig. 3.8).
The m-RNA inserts itself between the large and the small sub-units of the
ribosomes. The ribosomes provide the synthetic machinery for the assembly of
amino acids to form a protein using m-RNA as a template. Here each codon
(triplet of bases) on m-RNA serves as a template for a corresponding amino
acid.
Ribosomes
consist of two sub-units, one large sub-unit and one small sub-unit (Fig. 3.8).
The m-RNA inserts itself between the large and the small sub-units of the
ribosomes. The ribosomes provide the synthetic machinery for the assembly of
amino acids to form a protein using m-RNA as a template. Here each codon
(triplet of bases) on m-RNA serves as a template for a corresponding amino
acid.
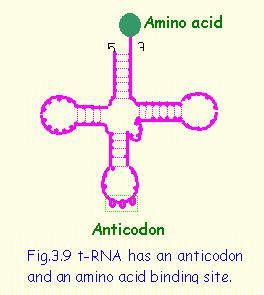
t-RNA
t-RNA is a special type of RNA which binds
to a specific amino acid and transfers it to the growing polypeptide chain (Fig
3.9). It consists of a single strand of RNA folded to form three loops. It has, at the 3’ end of the RNA, the attachment site for a
specific amino acid. On the second loop there is a triplet of bases, which are
complementary to the codon corresponding to the amino acid, called an anticodon. The anticodon on t-RNA recognizes a codon on
m-RNA and transfers the appropriate amino acid to the growing polypeptide chain
in the ribosome. The t-RNA must first be activated by combining with the amino
acid and with GTP to provide energy for the chemical reaction.
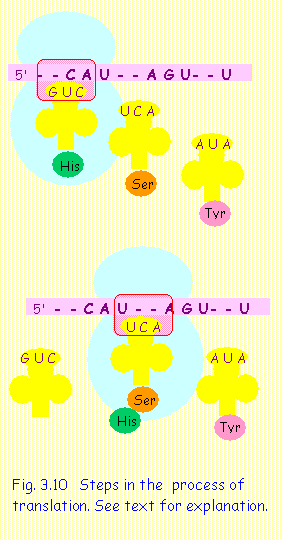 TRANSLATION: PROTEIN SYNTHESIS
TRANSLATION: PROTEIN SYNTHESIS
The complex process of translation leading to protein synthesis is summarized below and illustrated graphically in Fig. 3.10:
1. m-RNA inserts itself in between the large and the small sub-units of the ribosomes starting at the 5’ end; translation proceeds in 5’ to 3’ direction. In this example three codons are shown (CAU - AGU - UAU)
2. The codons are exposed, one at a time at the "A" (aminoacyl) site of the ribosome; here the codon CAU occupies the site - this codon codes for the amino acid histidine (his).
3. A t-RNA having an anticodon (GUC) at one end and the amino acid histidine at the other, attaches to the exposed codon (CAU) and transfers the corresponding amino-acid
4. The t-RNA detaches itself and m-RNA moves to expose the next codon (AGU). The t-RNA having the corresponding anticodon (UCA) and the amino acid (serine) attaches to the codon and transfers its amino acid to the growing polypeptide chain. GTP (a substance similar to ATP) provides energy for this process.
5. Another t-RNA is shown ready for the next codon and the cycle is repeated.
***********************
SINGLE-STRANDED AND DOUBLE- STRANDED NUCLEIC ACIDS
Biochemical analysis can be used to estimate the relative quantities of bases in nucleic acids. The proportions of bases (adenine, guanine, thymine and cytosine) vary in different specimens of DNA. However, in all double- stranded DNA, because of the specific base pairing (A - T and C - G) the proportion of thymine is equal to that of adenine and the proportion of cytosine is equal to that of guanine. In contrast, in single-stranded polynucleotides, whether RNA or single-stranded DNA, the proportion of the base is not equal. This is an important distinguishing feature between single- stranded and double- stranded nucleic acids. The presence of uracil and the absence of thymine distinguish RNA from DNA.
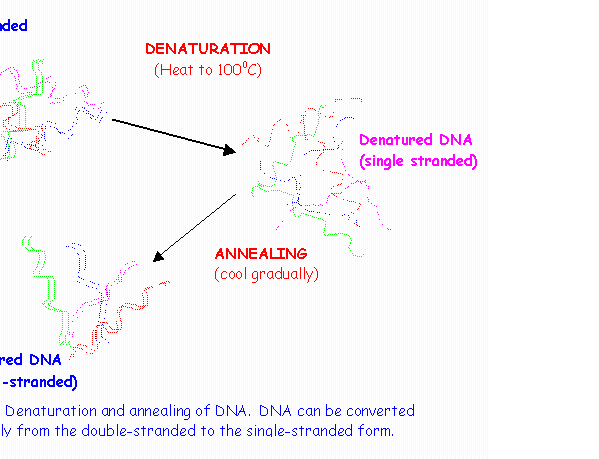
DENATURATION AND RENATURATION OF DNA
When a solution of DNA is heated slowly to about 1000 C the H-bonds, which bind the two strands of DNA are broken and single-stranded DNA molecules are formed. This is called denaturation or melting of DNA. If this solution is then cooled rapidly the DNA remains denatured or single-stranded. However, if the solution is reheated and cooled gradually, double stranded DNA will again be formed. Through specific base pairing the single strands can identify their complementary strand and H-bonds are reformed. This is called renaturation or annealing of DNA.
PROBLEMS
Problem 1.
If the sequence of bases on the template strand of DNA is 3'-A G C A T T C G A G A T -5', what is the
sequence on the coding strand of DNA?
Solution
The sequence of bases on the coding strand of DNA is worked out using specific base pairing. The two strands are antiparallel; therefore the complementary strand is in the 5' to 3' direction.
template strand: 3'-A G C A T T C G A G A T -5'
coding
strand: 5'-T C G T A A G
C T C T A -3'
Problem 2.
On analysis a sample of DNA is found to contain 30% adenine. What is
its percentage content of the other three bases?
Solution
Because of specific base pairing an equal amount (30%) must be thymine. Therefore A-T forms 60% of the bases. The remaining 40% must be formed by C and G which must be present in equal amounts of 20% each.
Adenine 30% - Thymine 30%; Guanine 20% - Cytosine 20%.
OTHER PROBLEMS FOR YOU TO WORK OUT.
1.  The
diagram shows a pentose sugar.
The
diagram shows a pentose sugar.
a) Label the carbon atoms on the pentose ring.
b) Insert a PO4 group in the correct position.
c) Insert an adenine base in the correct position.
d) What is the name of the resulting nucleotide?
e) Insert a whole thymine nucleotide in the correct position to form a dinucleotide..
f) Label the 3' and 5' ends of the dinucleotide formed.
2. The following is the sequence of bases on a single strand of DNA that was annealed with its complementary strand to form double stranded DNA.
5’ - G T T A C G G G C G G A A
C C G T A A T -3’
a) Write out the sequence of bases on the complementary strand.
b) Calculate the proportions of the four nucleotides A,T,C and G in the single DNA strand.
c) Calculate the proportions of the four nucleotides A,T,C and G in the double-stranded DNA formed after annealing.
d) Compare the A:T and C:G ratios of the single and double-stranded DNA. Explain why they are different.
e) Work out the values of (A + G) and (T + C) for the single and double- stranded DNAs. Explain the results.
3. Estimation of the proportion of bases contained in the genetic material of a virus gave the following result: Adenine 36%; Thymine 18%; Cytosine 26%; Guanine 20%. From these results determine which type of genetic material was present in this virus. Explain your result.
A particular stretch of double-stranded DNA contianed 50 thymine and 100 cytosine bases. What is the number of adenine and guanine bases in this stretch of DNA?
4. DNA estimations on three specimens of nucleic acid gave the following results:
A T C G U
specimen 1 20% 20% 30% 30% -
specimen 2 20% - 35% 15% 30%
specimen 3 30% 20% 30% 20% -
Identify whether each of the specimens was DNA or RNA and whether single or double stranded. Explain.
********************