Univsersity of Malta Tal-Qroqq, Msida MSD 06 Malta, Europe e-mail: cstaff@cs.um.edu.mt Tel: (356)-32902506 Fax: (356)-320539 |
University of Sussex Falmer, Brighton Sussex BN1 9QH England e-mail: chrisst@cogs.susx.ac.uk |
HyperContext is a new model for adaptive hypertext. HyperContext achieves adaptation of the information and hyper-links through explicit context. Objects of information in the hypertext obtain their context from their parent objects and in-links. When objects of information are accessed, they are interpreted according to the appropriate context of the parent object and link pair, prior to being presented to the user. All objects of information have a profile, a set of labels which together comprise a context-free description of the object. An object interpretation is a subset of the labels in the profile which comprise a description of the object relevant to the context in which it exists. Labels become links when they are associated with objects of information in some context. The same label can appear in different interpretations of an object of information, and in each interpretation the same label can be linked to different objects. HyperContext is a three-layer model. The Object Layer is an unstructured collection of object representations. The Structure Layer is a hypertextual representation of interpretations of the objects in the Object Layer. Users interact with HyperContext through the Presentation Layer. Three Information Retrieval methods, which support context-free and context-sensitive search, are also presented.
Keywords: Adaptive Hypertext, Context, Hypertext, Information Retrieval.
This paper introduces HyperContext, a new model for adaptive hypertext which is achieved through support for context. Context in hypertext is not new; context has always been present in hypertext systems. However, context is usually implicit. HyperContext makes context explicit and, consequently, reusable.
A hypertext system is a repository for information, where related objects of information (i.e., nodes containing information) are explicitly referenced through the use of hyperlinks, or links. The links are subsequently used to traverse the hypertext structure to move from one object of information (a parent) to another (a child). Objects are linked because some relationship exists between them. However, except for a few notable exceptions, the details of the relationship are usually lost. Some hypertext systems, such as gIBIS [10], use typed links, where the link type explicitly records the type of relationship that holds between the parent and the child. HyperContext takes a different approach. HyperContext supports discrete interpretations of information, each giving a different perspective of the information, as viewed from a specific parent and link. Consequently, if a child has two or more parents, each parent can have a different interpretation of the same information in the child. An interpretation is the information content of the object and a collection of keywords and key phrases (labels) that describe the information content. A label becomes a link when it is associated with another object. The interpretation of the child will be described by only those of its labels which are relevant to the interpretation of the parent and the link that was used to access the child. The labels used to compose object interpretations are taken from an object's profile, a superset of the labels that describe the object under all possible interpretations. HyperContext also supports information retrieval-in-context, using the interpretations of objects.
Currently, a partial implementation of HyperContext is wrapped around World-Wide Web [4] HTML [25] pages, but with appropriate interfaces, it can be wrapped around any hypertext system or information base.
Entities exist in an environment and may have a state and a pre-specified or dynamically determined behaviour. An entity's context is composed of those entities in the environment which are capable of interacting with it, possibly to influence its state and behaviour, to obtain feedback, or to communicate its intentions. Members of an object's context can interact with the object when some condition arises which permits the interaction.
In a hypertext, the environment is bounded and its entities are objects, links, and user models (if represented). All entities can have a context, but we will consider only the context of those entities which are capable of having actions performed on them. The members of an object's context are its parents and in-links, and a link's context is composed of its source and destination objects. The act of traversing a link creates the condition under which the parent can cause the child to behave. It behaves by presenting itself to the user (behaviour can be more complex with typed links and typed objects). In HyperContext, an object additionally changes its state by offering an a priori defined interpretation of itself. The interpretation is composed of the information content, a description (a set of labels) and a set of out-links.
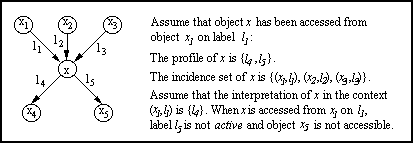
HyperContext is a new closed world model of hypertext that is explicitly adaptive. HyperContext takes the unique approach that an object of information x can have several interpretations, and each interpretation is dependent on a parent, link pair, (xk, lk), a member of its set of possible parents (incidence set) (see Figure 1). There is no equivalent of a user model in HyperContext, so the specific context is supplied by an object's parent and the link that is used to access the child.
An object's interpretation is composed of a set of labels which describe the object in that specific context. Labels are typically, but not restricted to, words and phrases that occur in the body of the text of an object (or in the case of non-textual or multimedia objects, keywords and key phrases that describe the object). A label exists primarily for descriptive purposes. However, if, in an interpretation, a label is associated with another object, then that label becomes a link. The object name and label form the context under which an interpretation of the child holds. For every context of an object there is a corresponding object interpretation. Whenever an object is accessed, the information content of the object is interpreted according to the specific context in which it is accessed. Only those labels and links specified in that interpretation are active.
HyperContext is a three layer model. The first layer, the Object Layer is a flat, unstructured collection of object representations. Objects are represented by profiles, where the profile is a superset of all labels in all possible interpretations of the object. In fact, a label cannot be used in an interpretation if it does not exist in the object's profile. The profile is not static - it can be changed. No link information is stored in the Object Layer.
The second layer, the Structure Layer, imposes a structure over the objects in
the Object Layer. The structure is created and extended by creating a directed
link from a label of an interpreted object to another object selected as the
link destination. However, at the same time, an interpretation for the child
must also be created, by selecting which of the child's profile labels are
relevant to the interpretation of the parent. So in effect links are not
created between objects in the Object Layer, but instead are created between
interpretations of those objects in the Structure Layer. The same label in
different interpretations of the same object can be linked to different
children. Not only is the description of an object dependent on its
interpretation, but so is the object's perceived location in the hypertext. In
order for an object representation to exist in the Structure Layer, the object
must have at least one parent which can provide it with a context. HyperContext
also recognises a special context, bottom
(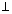 ). For those objects which
naturally have no parents (e.g., root nodes), or for those objects which
require an interpretation even when they are accessed directly (e.g., via a
hyper-leap, rather than a link), then
allows objects to have a context-free
interpretation. provides an
object with a context if the object is accessed
from outside HyperContext's closed world, rather than by following a link from
one of the object's parents in the hypertext. Every object has an
interpretation for ,
which is automatically created the first time an object
is represented in the Structure Layer. The interpretation for
is identical
to the object's profile, but can be modified to be a subset of the profile, or
even the empty set.
). For those objects which
naturally have no parents (e.g., root nodes), or for those objects which
require an interpretation even when they are accessed directly (e.g., via a
hyper-leap, rather than a link), then
allows objects to have a context-free
interpretation. provides an
object with a context if the object is accessed
from outside HyperContext's closed world, rather than by following a link from
one of the object's parents in the hypertext. Every object has an
interpretation for ,
which is automatically created the first time an object
is represented in the Structure Layer. The interpretation for
is identical
to the object's profile, but can be modified to be a subset of the profile, or
even the empty set.
The third and final layer is the Presentation Layer. Objects are interpreted and displayed to the user following a link traversal. A context session is maintained which stores information about the contexts and interpretations of objects accessed during the current session. A context session is terminated either when the user quits HyperContext, or when there is a context switch, by changing the context of the current object, or by hyper-leaping to an object.
HyperContext does not employ user models. Rather, when an object is accessed, the user can switch the context to the interpretation of the object which best reflects his or her needs, or uses HyperContext's information retrieval methods to search for appropriate information in context (see Section 4). Once the most relevant interpretation of the object has been selected the user can browse through the resulting hypertext, which will continue to adapt according to the links that are traversed and object interpretations that are visited.
A more formal description of HyperContext is in the Appendix.
HyperContext has three information retrieval methods to support information, or resource, discovery and to rapidly locate an area of a hypertext which contains information relevant to a user. The three methods are coined Traditional Information Retrieval (TIR), Information Retrieval in Context (IRC) and Adaptive Information Discovery (AID), respectively. A discussion of each follows.
4.1 Traditional Information Retrieval
One of the major problems in any general purpose hypertext is that there is no guarantee that all objects containing related information are linked. This is also the case with HyperContext. In HyperContext it is the interpretations of the information in objects that are linked, and different users with different requirements could interpret the same information differently, and see opportunities for highly idiosyncratic connections between objects. The existing connections between interpreted objects reflect interpretations of the information contained within the hypertext created by its authors and previous users, and it is not necessarily the case that a perspective which is relevant to a user will already exist, even though there may be the information within the hypertext which could support that perspective. So a path to an object which contains an interpretation of information relevant to a user may not yet exist. The only ways for the user to find the relevant information are by browsing or by using Traditional Information Retrieval (TIR) techniques.
There are two approaches that can be taken; a context-free approach, and a context-sensitive one. General-purpose Information Retrieval methods generally make no assumption about the organisation of documents, or information-containing objects. This is consistent with the lack of organisation of HyperContext objects in the Object Layer. In the context-free approach, TIR builds an index of keywords extrapolated from all the documents in the collection. Unlike several hypertext systems (Hypertext Information Retrieval systems e.g., [1] are notable exceptions), HyperContext describes each object in the Object Layer using a profile composed of descriptive labels. An index can be constructed from the profiles of each object to support information retrieval. A general-purpose information retrieval system either measures the degree of relevance (e.g., probabilistic IR [14], Vector Space [24]), or else determines whether a document is relevant without measuring the degree of relevance (e.g., the Boolean matching algorithm [13]). For example, a simple query could be to find those documents in the collection which contain specified keywords, e.g., query("computer" or "science"). The result of the function in a Boolean information retrieval system would be an unordered list of those documents which contain at least one occurrence of each keyword. A Probabilistic Information Retrieval system would also return a list of documents that contained at least one occurrence of each keyword, except that the list would be ordered according to the probability that the document is relevant to the query, based on, for instance, the number of times the keywords occurred in each document in relation to the size of the document and the probability that the keywords in the query would also occur in non-relevant documents, and other term features [15]. A probabilistic IR system is likely to give results of higher precision (i.e., be of "better quality" as judged by the user) than a Boolean IR system. However, the Boolean information retrieval model has been adopted for HyperContext as, at this stage, only a simple model of information retrieval is required.
The Boolean TIR approach is also extended in HyperContext, to give a context-sensitive approach. In the context-free approach, the search is performed on an index extrapolated from the profile of objects in the Object Layer. HyperContext, however, has a richer pool of descriptive information in the Structure Layer.
In HyperContext, the view is taken that it is not sufficient for information to be relevant to a query simply if it is "about" the query, which is the view usually taken in Information Retrieval. Rather, information may be relevant to a user if it is about the topic being sought and is relevant to the context in which the user is searching for information. In information retrieval the "topic being sought" is usually described by keywords in a user query. In general-purpose information retrieval systems, such as those described above, the index generated for each document can be viewed as being equivalent to the profile of a HyperContext object in the Object Layer. The interpretation of a HyperContext object in the Structure Layer is not only a finer grain description of an object, but also has a context - the context provided by the object's parent, link pair under which the interpretation holds. Consequently, the Boolean TIR method can be extended to search through an index extrapolated from the interpretations of objects in the Structure Layer, and the query can be extended to allow the user to specify that the labels to be searched for should be active in the same interpretation. Context-free search is merely a special case of the context-sensitive Boolean TIR system in HyperContext, with the exception that the list of relevant objects can be partially ordered to reflect whether the object has an existing interpretation which is relevant to the query, or whether the object is relevant only in its uninterpreted state via the profile. By selecting a relevant object from the list, the user effectively hyper-leaps from the current object to the selected object, adopting the context which supports the selected interpretation.
The Boolean model retrieves those objects which are `true' for the query, as determined by the matching algorithm. The definition of relevance differs depending on whether the search is context-sensitive or context-free. If the search is context-free then it suffices for the query terms to be matched against labels in an object's profile without reference to the context in which those labels are active. In context-sensitive search, the context in which the labels are active is taken into account.
| Label | Location | Context |
| Computer | http://a.host.edu/default.html | http://cs.edu.mt/index.html, CSAI |
| Science | http://a.host.edu/default.html | http://cs.edu.mt/index.html, example |
In Figure 2, a context-free search for ("Computer" and "Science") will find the object located at http://a.host.edu/default.html. However, because the labels are active in different contexts, the object will not be relevant to the query in a context-sensitive search.
A disadvantage of the TIR model results from the difference in the philosophies of the Boolean TIR method (as well as a large proportion of IR solutions in general) and HyperContext. HyperContext is a highly distributed information system. Each object knows only that is has descriptions of itself under a number of interpretations, and for each interpretation it has a parent and a possibly empty set of out-links. However, for efficiency, TIR requires a centralised index through which to search.
4.2 Information Retrieval-in-Context
In the TIR method described above, relevance is a relatively crude approximation. It is useful because through it, it is possible to find objects which may not be reachable from the object that the user is currently visiting. However, relevance can also be defined in terms of the relationship between two objects as evidenced by the fact that a link, or a path, exists between them. For instance, if two interpretations of objects are directly connected then this link provides strong evidence that the two objects are related in some context. Information Retrieval-in-Context (IRC) takes advantage of this evidence from HyperContext's Structure Layer. The assumption here is that through the query, the user is instructing the system to look ahead, down all possible paths emanating from the current object interpreted in some context, to find other objects which also meet the criteria of the terms expressed in the query. The structural information derived from the Structure Layer indicates that the object is relevant to the context of the current object (otherwise a path from the current object to the target object, i.e., the object which is relevant to the query, would not exist). The Boolean Information Retrieval (BIR) method can be used to determine if the object is relevant to the topic expressed in the query. The search terminates when a user set look-ahead limit is reached or when the paths are exhausted. The results are ordered such that the "closest" object (in terms of the number of intervening objects) is considered to be the most relevant.
A breadth-first search is performed, so that as soon as the first relevant object is found the user can proceed. The user can either hyper-leap to the found object, inheriting the appropriate context, or else the user can follow the recommended path to the object. The user may choose to follow the recommended path for a number of reasons. The user may wish to see the contents of the intervening objects to see how the target object is related to the node from which the user issued the query. This may be because the user hopes to find more information in order to be able to construct a more refined query. By following the recommended path, a user may discover that the target object is not likely to be relevant to his/her needs and may choose to deviate from the recommended path, by following a link that is active under the current interpretation but which will not lead to the target object. The system may then revise its recommendation by locating an interpretation of an object that meets the query criteria but that exists under the new context, once again recommending a path to follow.
If a user is dissatisfied with the recommended path or the target object at the end of that path, the user can discard the target object or recommended path and roll back to the original object from which the query was issued and follow the recommended path to the next relevant object. If a roll back is performed, the system should be able to use that feedback to re-evaluate the other relevant objects that were found in order to eliminate those objects which are also likely to be irrelevant given the feedback. This can be achieved by eliminating objects from the set of relevant objects that reside on the same path as the object or path that was discarded, for example.
4.3 Adaptive Information Discovery
In the previous two IR methods the search is initiated by the user through a query. In Adaptive Information Discovery (AID), HyperContext itself attempts to guide the user to the information that the system estimates as relevant to the user without requiring an explicit user query.
AID is a background process that attempts to make calculated guesses about what information might be relevant to the user by examining the context session. AID then searches for the information and offers it up to the user for consumption. AID can estimate what the user might be interested in by building descriptions of candidate relevant objects from the labels of the interpreted objects that the user has visited. This description would be composed of the labels that appear most frequently in the interpretations of visited objects, with particular emphasis on the labels associated with the links that were traversed.
The main point of this search method is that when interesting objects are found, they become candidates for creating a link to an object that has been visited in the context session. This new link is public and is consequently available to the user population.
AID generates an interpretation of what is calculated to be the information that the user is looking for. Once the interpretation has been generated there are several options available. The simplest is to determine if a similar interpretation of an object already exists, using TIR. If TIR finds an interpretation in context, and the user finds the object relevant, then the user is asked whether the object should be linked to a previously visited object. If no interpretation exists, then TIR can look for an object profile which is relevant to the generated object interpretation. In this case, if the user finds the object relevant, the user can create an interpretation of the object based on the relevant labels in the object's profile and link it to the appropriate object to which it is relevant.
It is also useful to know where the object is in relation to the objects in the context session. This aspect of AID is controlled by a look-ahead depth. The objects in the context session together with the other objects reachable from each object to the given depth, forms a context-free sphere. The context-free sphere contains all interpretations of each object, and so can be thought of as being 3-dimensional. If the object exists in the sphere, then AID can recommend a path to the object, if no context switching is involved, or, if context switching would be involved, it can assist the user to construct a new context path to the object. As links are directed, an object may be reachable from a previously visited object in the context session, rather than from the current object. A user may wish to "back up" to that object and follow the path from there. This is useful if the user is browsing in approximately the right area, but is navigating along a path that will not lead to the object being sought. AID can move the user to approximately the right object from which to resume browsing, recommending the path the user should follow. Alternatively, the user can link the found object to whichever object he/she thinks appropriate.
The IRC and AID search methods in HyperContext are exposed to cycles and spirals. A cycle occurs when an object interpretation is revisited in a particular context. Cycles can be detected by keeping a history of the contexts in which an object has been previously visited. If, when an object is visited, it transpires that it has previously been visited in exactly the same context, then the search down that path is terminated, and the search passes to the next object, if any, in the breadth-first traversal. A spiral occurs when a previously visited object is revisited in a different context. In this case, the search is not stopped, because the interpretation of the object in each context can be different, and the object could be linked to other different objects.
Massive hypertext systems such as the World-Wide Web are becoming increasingly difficult to use as they grow in size, and as the information contained within them becomes more diverse. Like information retrieval systems, hypertext systems are used for information discovery. However, unlike information retrieval systems, there is no underlying assumption that users are able to express their information need as a formal query, but rather they will know the information they are looking for when they see it. Consequently, users are unlikely to know what information they are seeking, but by navigating through objects in the hypertext they will either discover the information, or else will discover information which will enable them to express their information need. Of course, hypertexts can also support "aimless" browsing, where users have no pre-determined information need but, through the course of their wanderings, could develop an interest in a particular subject. Catledge and Pitkow [9] discuss various browsing strategies in the World-Wide Web.
5.1 Problems in non-adaptive hypertext systems
In hypertext systems, users will follow links which appear to be likely candidates for bringing the user closer to the information being sought. However, it is first necessary for a user to find his or her way to the part of the hypertext containing information about the relevant domain (which may be located in many disconnected areas), and then to continue browsing from there. Once in the local area, there is no guarantee that this particular area contains the information being sought, either. Also, links do not necessarily adequately describe the information to be found in the child, so a promising link may lead to irrelevant information or relevant information may be hidden behind an innocuously named link. The reasons for this can be traced back to the rationale behind the creation of the link.
A link is created for a particular reason - there is some information in an object which, in one way or another, is relevant to information in another object (We do not discuss links which allow rapid relocation to a particular position in an object). However, the details of the relationship are not usually available for inspection, and unless the user interprets the information in the parent as the creator of the link intended, then the reason for the user traversing the link is unlikely to be similar to the author's reason for the creation of the link. Hence, there is a chance that the information contained in the child is unlikely to be relevant to the user.
This problem is further compounded by principles of Human-Computer Interaction. In order to avoid overloading a user with choice (inducing cognitive overload), only a few of the links to potentially relevant information are provided [7]. Consequently, unless the user is specifically looking for the information that the author has provided (including links), then although information relevant to the user may exist, it is not necessarily accessible from this point in the hypertext.
Such hypertexts do not necessarily help the user to discover information. Users with different needs and requirements are all sharing the same collection of information. Tools to support information retrieval in hypertext systems assume that the result of a user query should be a specific object. The user is lifted from one part of the hypertext to another, with no indication of where the target object is in relation to the rest of the hypertext, even though the power of browsing through a hypertext is the ability to follow a path through objects, where an object is related to its neighbours in the path. The system cannot estimate what the user might be looking for and suggest a path to that information. Also, once a user has potentially invested a significant amount of time to find the information there is no direct way of influencing the link structure to assist a future user with the same needs, short of creating a new object which describes the problem domain and contains links to other existing information. Even this is not necessarily sufficient, because it is not possible to create links between two or more objects which contain related information without the co-operation of the owners of the objects.
5.2 Adaptive Hypertext
Adaptive Hypertext systems attempt to surmount these problems by estimating users' needs and requirements to adapt the links and information content of the objects in the hypertext [7]. By adapting the links from an object, the chances that the links will lead to relevant information are increased, and by adapting the content of objects the chances of being exposed to irrelevant information are decreased.
Another large difference between adaptive hypertext and non-adaptive hypertext is that the user community benefits from the adaptations of the hypertext, that is, the results can be shared throughout the community, or can be bounded to limit the extent of the sharing to specific user groups (e.g., Microcosm [11], VIKI [19], PUSH [12], and HyperMan [23]).
Also, adaptive hypertext systems actively support the information discovery process. In addition to potentially adapting links, systems such as WebWatcher [3] and HyperMan employ mechanisms to allow a user to rapidly access relevant information. The major difference between the adaptive hypertext and hypertext information retrieval support approaches is that the advice given by adaptive hypertext systems is usually learned by observation.
Many adaptive systems use some form of user model to represent individual user's needs and requirements. The user model can also be generalised over a group of users with similar needs and requirements. The model is initialised explicitly by the user and is then updated by the system through observation and user feedback to build a more accurate model. The user model plays a supportive, rather than didactic, role. The user is ultimately in control and user feedback on the system's recommendations add to the system's experience.
The hypertext adaptation process is usually two-level [22]. In such systems, the underlying hypertext or information base in use can be arbitrary and non-adaptive. The user navigates through the underlying hypertext and the overlying adaptive agent modifies the content and links once a link has been selected for traversal. Usually, link modification in two-level systems is achieved by highlighting one or more links from the object to indicate that the agent estimates that following those links will ultimately lead the user to the information being sought (e.g., WebWatcher [3]). In some systems, the destination of links can be changed to lead the user to relevant information (e.g., SNITCH [21]).
Adaptive hypertext systems can be applied to the World-Wide Web (WWW). Not only is the WWW becoming increasingly difficult to use because of its size, disparate information, numerous authors and multitude of styles of presenting information, but the WWW is also a readily available and accessible resource which demands shareable customisability if it is to become anything other than a dinosaur [2].
All adaptive hypertext systems are concerned with determining whether there is information which is relevant to the user given a goal (the information the user is seeking) and the user model (or an approximation of it). Adaptive hypertext systems support adaptive navigation, adaptive presentation, or both [7].
Adaptive navigation is concerned with recommending to the user a path to take him/her to an object containing relevant information. Adaptive presentation, on the other hand, is concerned with adapting the information content of an object so that it contains relevant information.
Adaptive navigation is essential if many users with different needs are sharing a massive, heterogeneous hypertext. Mathé and Chen [20] construct a relevance network which records users' information access patterns, in the underlying, non-adaptive hypertext, to locate relevant information. These access patterns (initially similar to paths in the underlying hypertext) are generalised through further observation, and eventually provide users with the ability to access relevant information more rapidly (i.e., via shorter paths) than would otherwise have been possible. The length of the path is more or less equivalent to the number of steps the relevance network needs in order to establish what information the user is seeking. WebWatcher [3], on the other hand, does not seek to override, or change, links in the underlying hypertext, but rather leads users to potentially relevant information by recommending which link or links to follow from the current object. WebWatcher learns from user feedback. Users are asked to state the information they are looking for at the beginning of a session, and when they find the information or give up searching they are requested to inform WebWatcher of the outcome. Bollen and Heylighen [5] experiment with a randomly connected network to establish if the network would eventually stabilise if users were permitted to create shared associative links between objects. The order in which objects are offered depends on the weighted strength of the links. Links are strengthened according to frequency of use, transitivity (enabling paths to relevant information to be shortened) and symmetry (enabling forward references to strengthen backward references). Bollen and Heylighen discovered that an initially randomly connected network will stabilise relatively quickly, and that it can quickly adapt to change, both in the information content of the hypertext, and in the information need patterns of its users.
Adaptive navigation can be enhanced, or sometimes subsumed, by adaptive presentation. In certain environments (e.g., learning and tutoring environments) it is preferable or necessary to adapt the information that is presented to a user once they have arrived at a particular object. Kay and Kummerfeld [16] build structures within the object content which will be conditionally displayed depending on user preferences or requirements. Brusilovsky [8] and Espinoza and Höök [12] dynamically generate the object on the fly. KN-AHS [17] dynamically adapts the content based on assumptions about the user's conceptual knowledge. These assumptions are drawn from user actions observed by KN-AHS (e.g., requesting an explanation of a word or phrase) and are reported to a separate user modeling shell system (BGP-MS [18]). When a user attempts to access another hypertext object, BGP-MS provides KN-AHS with enough information for it to automatically expand the content to include explanations, etc., of words and phrases that system anticipates the user will want to see.
HyperContext has direct support for adaptive navigation. As yet, it does not support adaptive presentation - in the sense that the actual content of objects is adapted. However, HyperContext supports adaptive interpretations of objects in which the description of an object changes according to the context in which a user is viewing the object. Adaptive navigation and adaptive interpretations are inseparable in HyperContext, and the same label can be linked to different objects depending on the interpretation.
A test site is being constructed for HyperContext. Tools to automatically create profiles and interpretations for Web pages are being designed. Although the automatically created interpretations may not be accurate to begin with, after the hypertext has been used and modified by its users, we expect a significant improvement in HyperContext's ability to assist with browsing and Information Retrieval.
The test site will be compared with another HyperContext site which mimics the WWW (i.e., there will be no interpretations of objects, and users will be presented with the same object of information and its links regardless from where it was accessed). Users of the test site will also not be able to create new links out of existing objects. They will, however, be able to create new objects in a similar way to the WWW. Finally, users of the second test site will not be able to make use of the IRC and AID information retrieval functions.
Currently, HyperContext objects are simple. Future work will consider creating complex object types, such as composite objects, as well as objects which exist simply to support the information search and retrieval process.
HyperContext, a new model for adaptive hypertext, has been presented. With appropriate interfaces, HyperContext can be wrapped around any hypertext system or information base to provide them with adaptive features.
When a link is created between two objects, an interpretation of the child is defined that is consistent with the interpretation of the parent from which the two object will be linked. When a user browses through the hypertext, traversing a link triggers the destination object to present the appropriate interpretation.
Three Information Retrieval methods are included which enable a user to search for arbitrary information or information that exists in the current context path. Additionally, Adaptive Information Discovery estimates a user's interests and searches for the information. A user can be guided to the information once it has been located.
New links and interpretations created by users are immediately available to the user community.
Juanito Camilleri, for his support and ideas, Steve Easterbrook, Nathalie Mathé and Jim Chen are gratefully acknowledged.

[1] Agosti, M. and Crestani, F. (1993). A Methodology for the Automatic Construction of a Hypertext for Information Retrieval. In Proceedings of the 1993 ACM Symposium on Applied Computing. Indianapolis, USA, February 1993.
[2] Andrews, K., Kappe, F., Maurer, H., and Schmaranz, K. (1995). On Second Generation Network Hypermedia Systems. In ED-MEDIA `95. Austria.
[3] Armstrong, R., Freitag, D., Joachims, T., and Mitchell, T. (1995). WebWatcher: A Learning Apprentice for the World Wide Web. In 1995 AAAI Spring Symposium on Information Gathering from Heterogeneous, Distributed Environments.
[4] Bernes-Lee, T., Cailliau, R., Luotonen, A., Nielsen, H., and Secret, A. (1994). The World-Wide Web. In CACM 37(8).
[5] Bollen, J. and Heylighen, F. (1996). Algorithms for the self-organisation of distributed, multi-user networks. Possible application to the future World Wide Web. In Trappl., R. (ed.). (1996). Cybernetics and Systems `96.
[6] Brusilovsky, P. and Beaumont, I. (eds.) (1994). Workshop on Adaptive Hypertext and Hypermedia. In Fourth International Conference on User Modeling 1994. On-line version available at http://www.education.uts.edu.au/projects/ah/AH-94.html.
[7] Brusilovsky, P. (1996). Adaptive Hypermedia: An Attempt to Analyse and Generalize. In Brusilovsky, P., Kommers, P., and Streitz, N. eds. Multimedia, Hypermedia, and Vitural Reality: Models, Systems, and Applications. Springer. Berlin.
[8] Brusilovsky, P., Schwarz, E., and Weber, G. (1996). ELM-ART: An Intelligent Tutoring System on World Wide Web. In Proceedings of ITS'96.
[9] Catledge, L.D., and Pitkow, J.E. (1995). Characterising Browsing Strategies in the World-Wide Web. In Computer Networks and ISDN Systems 27.
[10] Conklin, J. and Begeman, M.L. (1987). gIBIS: A Hypertext Tool for Team Design Deliberation. In Proceedings of Hypertext `87.
[11] Davis, H., Hall, W., and Heath, I. (1993). Media Integration Issues within Open Hypermedia Systems. In Proceedings of IEEE International Symposium on Multimedia Technologies and Future Applications, 21-23 April, 1993, Southampton, UK.
[12] Espinoza, F. and Höök, K. (1996). An Interactive WWW Interface to an Adaptive Information System. In Proceedings of the Workshop on User Modelling for Information Filtering on the World Wide Web, Fifth International Conference on User Modelling, Hawaii, January 2-5 1996.
[13] Fox, E.A., Chen, Q.F., and France, R.K. (1991). Integrating Search and Retrieval with Hypertext. In Berk, E. and Devlin, J. (eds.) (1991). Hypertext/Hypermedia Handbook. McGraw-Hill.
[14] Fuhr, N. (1992). Probabilistic Models in Information Retrieval. In The Computer Journal 35.
[15] Fuhr, N. (1993). Representations, Models and Abstractions in Probabilistic Information Retrieval. In Opitz, O., Lausen, B., and Klar, R. (eds.): Proceedings of the 6th Annual Meeting on Information and Classification. Springer, Berlin et al.
[16] Kay, J. and Kummerfeld, B. (1994). Adaptive Hypertext for Individualised Instruction. In [6].
[17] Kobsa, A. Nill, A. and Fink, J. (forthcoming). Adaptive Hypertext and Hypermedia Clients of the User Modeling Systems BGP-MS. To appear in Maybury, M. (ed.) (forthcoming). Intelligent Multimedia Information Retrieval.
[18] Kobsa, A. and Pohl, W. (1995). The User Modeling Shell System BGP-MS. In User Modeling and User-Adapted Interaction 4(2).
[19] Marshall. C.C., and Shipman, F.M. (1995). Spatial Hypertext: Designing for Change. In CACM 38(8).
[20] Mathé, N. and Chen, J. (1994). Adaptive Dynamic Hypertext based on Paths of Traversal. In [6].
[21] Mayfield, J. and Nicholas, C. (1993). SNITCH: Augmenting Hypertext Documents with a Semantic Net. In International Journal of Intelligent and Cooperative Information Systems 2(3).
[22] Mayfield, J. (1994). Two-level Hypertext Models as an Underpinning for AHSs. In [6].
[23] Rabinowitz, J., Mathé, N. & Chen, J. R. (1995); Adaptive HyperMan: A Customizable Hypertext System for Reference Manuals. In Proceedings of the AAAI Fall Symposium on Artificial Intelligence Applications in Knowledge Navigation and Retrieval, Cambridge, MA, Nov. 10-12.
[24] Salton, G. and Allan, J. (1994). Text Retrieval Using the Vector Processing Model. In Proceedings of the Third Symposium on Document Analysis and Information Retrieval. University of Nevada, Las Vegas. 1994.
[25] World Wide Web Consortium. (1996). Hypertext Markup Language. On-line version available at http://www.w3.org/pub/WWW/MarkUp/.