The instructions for the synthesis of proteins and RNA are stored in coded genes made of DNA, as a continuous string of nucleoside bases in complementary pairs Adenine-Thymine, Cytosine-Guanine. Genes consist, on average, of about 1000-1500 bases.
For protein synthesis, every 3 bases code for an amino acid:
TCAGTCAGfirst basesecond base
G-C
G-C
T-A
T-A
G-C
A-T
C-G
C-G
T-A
G-C
Leu
Thr
(Iso = Isoleucine, Asg = Asparagine, Gln = Glutamine. Note how the acidic, basic, hydrophilic, and hydrophobic amino acids are grouped together.)
There are 10 bases for each turn of the double helix. The bases are oriented oppositely on the two strands.
DNA is in itself protective of its bases, because these occur in joined pairs inside the helix. In addition, it is stored coiled around proteins, which assemble together to form coiled structures called chromatin, in diameter.
Positively-charged histone or HU proteins are needed to bring the negatively-charged DNA together, and bind tightly to them; yet they can open up when the DNA is needed.
Transcription: DNA → RNA
When genes need to be used, their information needs to be transcribed faithfully and translated into proteins.
To start the process, the local packaging proteins around a gene are removed to leave a stretch of DNA. Most of the time, genes are switched off by having repressor protein molecules attached near their starting point (promoter). A gene may be more permanently switched off by methylating (CH3-) its adenines or cytosines at the promoter site.
To transcribe the gene, two events must happen:
a triggering activating molecule causes the repressors to detach;
other triggering molecules activate protein transcription factors which are then able to attach near the starting point of the gene.
The main copying protein, RNA polymerase, attaches to the transcription factor and then to the DNA.
Powered by ATP, it starts copying DNA (by first unwinding the DNA), outputting RNA. RNA differs from DNA only in having one extra O atom (Uracil instead of Thymine); it naturally disintegrates after a while. In general, the cell is continually purified of RNA, while DNA is preserved and repaired. RNA polymerase makes few errors, about 1 in 10k bases.
When the RNA polymerase reaches the end of the gene, it finds special repeating sequences, or special small proteins, which cause the outcoming RNA to coil up on itself, halting the polymerase. The RNA is then cut out, while the polymerase detaches from the DNA.
Several RNA polymerase proteins are usually copying a single DNA gene, as seen in the inset photo: the dark line is DNA, with hundreds of RNA being copied out. The copied RNA is then "processed" by other proteins, trimming out the tail.
The whole transcription process may be stopped short by certain protein factors.
The resulting RNA may be of two types:tRNA with shepherding protein
Amino Acid (here phenylalanine)3-base code (here AAG to recognise TTC)tRNA (one of 31 = 4×4×2-1 types)
Messenger RNA (mRNA) will have its coded sequence "translated" into polypeptides; a second polymerase complex adds a hundred or so adenosines to an end and links them in a loop; the mRNA is then protected by small "zinc finger" proteins, or bound by a repressor 'riboswitch' protein to stop immediate translation.
Ribozyme RNA coils up into ribozymes, that act as catalysts (like enzymes, except they are made of RNA), or signals, or inhibitors etc. The most important ribozymes are:
transfer RNA (tRNA) are the physical embodiment of the genetic code: each one has a 3-nucleotide sequence at one end, and a specific amino acid attached to another end by specific enzymes; the amino acid is protected by a protein which is released only when activated; (tRNA is not any smaller to allow the enzymes that attach the amino acid enough leeway to correctly identify it; faulty tRNA has grave consequences).
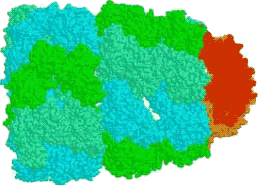
rRNA coils into parts of a ribosome, which is the enzyme that does the translation: creating the polypeptides from mRNA.
rRNA and tRNA are continuously transcribed by special polymerases that do not need the initial stages of initiation, because they need to be present all the time to synthesize proteins. In fact, several gene copies code for them, to keep up with demand, and just in case some fail — tRNAs are probably the most plentiful macro-molecules inside the cell.
Translation: mRNA → Protein
rRNA consists of two parts. The smaller part is the first to attach to an mRNA, at the starting methionine codon; a small protein covering the adjacent space in the rRNA is released, allowing a tRNA for methionine to link up with the methionine codon there. (This methionine is later cut out.)
The protein covering the tRNA detaches, and allows the larger part of the rRNA to attach to the smaller rRNA, completing the ribosome.
Several tRNA near the entrance of the ribosome may try to attach there, but only the one whose 3-nucleotides match their complementary 3-nucleotide code on the mRNA is stable enough.
A special protein enters the ribosome and pushes the two internal tRNAs further in, dragging along the attached mRNA.
More tRNA enter inside the ribosome; each time, the amino acid from the tRNA is bonded to the amino acid from the previous tRNA. The used tRNA is pushed out of the ribosome; it will meet an enzyme that will "recharge" it with its correct amino acid. This process continues, step by step, with several tRNA attempting to enter the ribosome, but failing until a correctly matched tRNA enters. The ribosome moves along the mRNA, every time adding an amino acid from the tRNA to the growing peptide, at a rate of about 15 amino acids/second, and using about 4-5 ATP molecules per amino acid.
When the ribosome reaches one of the stop codons UAG, UAA, or UGA on the mRNA, there are no tRNA with these 3-nucleotides. Instead a special release protein matches up, which "closes" the poly-peptide chain, and causes the ribosome to split up into its large and small parts.
Enzyme recharging tRNA
Several ribosomes in turn attach to the mRNA at the starting point. As they move along, each one produces the polypeptide chain of amino acids coded for by the mRNA. Within of switching on a gene, are being produced. The lifetime of a single mRNA is about 1-15-100mins.
mRNA is eventually cut up by a large exosome complex, and recycled into nucleotides by enzymes.
The polypeptide normally folds up into its intended shape. It may be "processed" further by clipping some amino acids, adding cross-linking bonds, or adding some functional groups. For example, small polypeptides tend to wiggle too much to fold properly, so a longer polypeptide is coded for, which folds well, and the extra part is cut off by an enzyme.
When the temperature is too high, the polypeptides take longer to fold, or simply remain unfolded. This is dangerous for the cell, as misfolded polypeptides will often have exposed hydrophobic parts, and these will stick to other misfolded proteins' hydrophobic parts, forming aggregates that clog the cell. To prevent this from happening, special small "chaperone" proteins protect the hydrophobic parts of an unfolded polypeptide, until they reach a large chaperone protein, which allows the polypeptide to enter and fold properly. Other chaperones force a mis-folded polypeptide through a pore, giving it a second chance to fold properly.
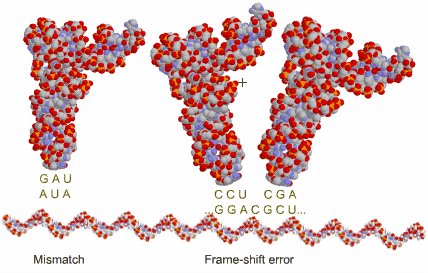
Some errors occur in translation, at less than 1 error every 100k amino acids:
1 in 500: a wrong tRNA is accepted in the ribosome, even though it does not match the mRNA codon; this includes those few (1 in 10k) tRNA that were previously matched to the wrong amino acid;
1 in 1000: a tRNA attaches to a 3-nucleotide further down, so that there is a frame-shift; when this happens, it is quite likely (3 in 64) that it soon meets a stop codon, forming a useless polypeptide;
rarely, the ribosome gets stuck at the very end of an mRNA because no stop codon was encountered; a special tmRNA enters such stuck ribosomes, cuts off the protein and attaches a short mRNA to free the ribosome.
Even though the error rate is low, the mRNA is quite long, and this results in about 0.1% of polypeptides being seriously faulty. Faulty or old proteins are marked by ubiquitin and are doomed to be cut up into peptides inside a large hollow proteasome.
Gene Regulation
Genes work in a self-regulating network. Some are switched on/off by a feedback mechanism, e.g. when the concentration of some molecule in the cell reaches a critical level. Other genes are switched on/off by an external stimulus through receptors and a cascade multiplier effect.
A few external molecules activate receptor proteins on the membrane surface which then transmit the signal via new messenger molecules inside the cell, which go on to activate other proteins or trigger the gene repressor molecules to detach.
In one common type, the active receptors link up, causing their interior protein part to also join, thus releasing the messengers. These messengers are continually reattaching to their protein.
receptorsmessengers
Another type of receptor breaks up transducer proteins (e.g. "G-proteins"), and these activate the synthesis or pumping of messengers (e.g. cAMP, Ca2+, NO, cGMP, ...).
receptormessenger amplifierG-protein (animals)
In most cases, it is phosphorylation or GTP that is passed from one messenger to the next.
Messenger proteins usually require several triggering molecules before they pass on the signal, for reliability and reduced sensitivity. Some act as AND or OR logic gates on signals.
If a signal persists, the receptor-messenger pathway becomes less sensitive to the signal in one way or another.
Different external stimuli — food, acid, poisons, light, cold, heat shock, ... — trigger different signal pathways.
Signals that activate or repress proteins already present in cell act in seconds; those that affect genes take half an hour or so. Signals only have a temporary effect.
In this simple model of lactose metabolism, a repressor stops RNA polymerase from transcribing mRNA. When present, lactose binds to the repressor causing it to detach and allows transcription to proceed. The gene codes for a protein (lactase) which breaks down the lactose. When no more lactose is present, the repressors are free to attach to the repressor site once again. Both proteins and mRNA are continually removed.
This model is only schematic: actual genes are relatively much longer, more proteins per mRNA are produced, and the real process takes long minutes.
DNA Repair
Damage to ribosomes, mRNA, etc. leads to faulty proteins, but the effect is only temporary. But damage to DNA is life-threatening, since information that is lost is gone forever — so it has to be constantly repaired. There are various sources of damage:
Oxygen radicals (O2-, H2O2, OH, poisons, etc.) can oxidize bases, e.g., they change guanine, allowing it to pair with adenine; or they can replace guanine or adenine completely; or they can deaminate them, changing say cytosine into uracil. Cells have anti-oxidant enzymes that convert O into hydrogen peroxide and this back to oxygen and water.
Radiation (UV, X...) also causes chemical reactions, the most common being that two adjacent thymines fuse together, or that a bond on the DNA strand breaks.
Averaged out, each base has about chance of being damaged every day. Even so, a whole genome will surely incur hundreds to thousands of lesions daily, and the cell needs to repair them as far as it can in order to survive.
Repair is possible because DNA consists of complementary strands; it is much rarer that damage is done to paired up bases simultaneously (1 in 1010).
A number of proteins scan the DNA continuously; each looks for its specific type of damage. One type simply breaks up fused thymines; others look for damaged or mismatched bases (e.g., uracil, which should not be present in DNA).
Other proteins, called nucleases, are also scanning the DNA, looking for these "holes"; their job is to "scissor" out stretches of DNA strands at the damaged site. For mismatched bases, they guess which one is correct by sensing which strand has nearby methylated sites.
A larger protein, DNA polymerase I, then attaches and fills in the missing bases.
Finally, one last protein, DNA ligase, is also scanning the DNA looking for cuts in the DNA strands, such as the one left by the DNA polymerase. When it finds one it joins the free DNA strands together.
A complete (double-strand) DNA break is much harder to repair: 'Ku' proteins try to reconnect the ends, and a ligase joins them together.
Another difficulty encountered by the extremely long strands of DNA is that they are liable to get entangled or supercoiled. Cells use a simple and effective method for dealing with this.
A protein, topoisomerase, looks for tangled DNA strands, cuts out one helix, allowing the other to pass through, then relinks the original helix.
Other proteins (annealing helicases) cut a super-coiled DNA helix, lets them unwind, then reattach the strands together.
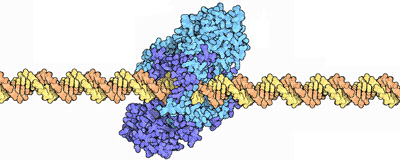
Replication: DNA → DNA
DNA replication starts when special proteins uncoil part of the DNA. Immediately other proteins attach to the single strands to prevent them from rejoining, while a helicase protein attaches at the front part of the reverse strand.
The unzipped strands have opposite directions, so replication is not a straightforward affair: the main copying protein can only add bases to a pre-existing backbone, and this in one direction only. So a special RNA primer adds a short stretch of complementary RNA to the forward strand, then attaches next to the helicase. The first strand will be copied in a continuous fashion, but the second one is in the reverse direction — it needs an elaborate mechanism for copying.
The rest of the proteins assemble into the replisome: the DNA polymerases are the main copying machines; the clamp with the clamp-loader attach to connector proteins, around the reverse strand. As the replisome replicates, the DNA in front of it is continually being super-coiled; special gyrase proteins unwind the DNA.
The RNA primer adds a short stretch of RNA to the reverse strand, and the clamp-loader passes the clamp with the primed DNA to the DNA polymerase; this can start copying and proof-reading the strand, until it reaches a finished part of DNA. This causes it to stop, detach its clamp, and tells the RNA primer to start the cycle again. The lagging strand of 2k DNA bases is replete with primed RNA, and empty bases (skipped or cut out by the proof-reader); this is converted to DNA by the cell's repair machinery. The ring clamps prevent the polymerases from detaching, thus speeding the process.
The replisome manages to copy at a rate of up to . Yet the DNA polymerase, with its proof-reader, only makes a mistake about every bases. These can be either:
copied wrongly,
skipped,
copied inverted,
duplicated,
when there is a slight repetition, such as CATATG, there may be a slippage forward or backward, i.e., a delete or insert;
more rarely, the polymerase gets detached and reattaches at a different place, resulting in a larger delete or repeated section.
Thus once every replications on average, a gene changes slightly. Most often, such changes cause the associated protein to fold wrongly or to be too short, increasing the chance of cell death. But there’s a small probability (1 in 30?) that the change in the gene is unimportant (neutral substitution or non-synonymous but depends on where in gene), and the resulting protein or ribozyme is still functional — or perhaps even better, when the original one was not very good because the environment has changed.
Over thousands of generations, cells therefore end up with different variations of the gene, called its alleles; an equilibrium distribution is established, with each allele occurring with probability where is the mutation rate creating the allele, and is the death rate of the cell removing the allele.
When a whole gene is duplicated, one copy slowly degenerates (over generations) into a non-functional pseudo-gene then junk DNA and slowly lost.
Genomes
The smallest viable genome is about genes, half coding for enzymes involved in metabolism and the membrane, and half for transcription, repair and replication of DNA. But such cells would be too slow to react and to reproduce, to compete with other cells in the wild.
The smallest living genomes ( genes) belong to parasites that have a stable environment.
The smallest genome of a free-living cell is about genes. There is no upper limit to how large a genome can be, except that it takes longer to copy.
Number of bases (in C.elegans)
Genes are typically bases long, and are situated randomly on either strand. The smaller proteins are transcription factors and effectors, while the longer ones are enzymes, structural proteins, ...
Viruses
Viruses are small lengths of nucleic acids that take advantage of the cell's machinery to replicate themselves.
RNA viruses (60%) are single stranded RNA ( bases), that is mistaken by the cell for mRNA. It is decoded by the cell's ribosomes to produce two sets of proteins:
replicator protein, takes the single-stranded RNA, and adds complementary bases to give double-stranded RNA, which then unzips; within minutes copies of its own RNA, and of its complement, are produced in large numbers;
capsule proteins to encapsulate the RNA, with 'spike' proteins that allow the virus to enter the cell, at some stage.
A minority (<1/3) of RNA viruses, have the complementary RNA instead; they need to bring along the replicator protein to start off an infection; or they are double-stranded RNA, and need an RNA polymerase with them to produce the first viral mRNA.
DNA viruses (30%) are double-stranded DNA ( bases), that is mistaken by the cell for genes. It is transcribed (even repaired and replicated) by the cell to produce viral mRNA. Because they can be larger without being detected, they can code for more and better proteins:
replicator and capsule proteins;
repressors to inhibit an adverse reaction by the cell;
transcription factors and activators that cause the cell to produce more replisomes;
docking proteins to help the virus enter a cell;
lysing proteins that kill the cell to help the virus get out.
Some small (5k bases) DNA viruses, start off as RNA which is "repaired" by the cell into DNA. They are too small to code for activating proteins, so they only replicate with the cell.
Retroviruses (10%) are RNA or DNA (about bases) that bring along a protein with the ability to convert its RNA into DNA (reverse transcription) and a protein that splices this DNA into the cell's genome (integrase); so they replicate automatically when the cell transcribes its DNA into mRNA, and the protein reverse transcribes it into DNA. They may lie dormant for long times, until switched on by the cell.
Viroids, (less than 500 bases) replicate using the cell's RNA polymerase; they are too small to code for replicators and protein coats. Satellite viruses (1-2k bases) code only for one capsule protein; they require another virus replicator for this.
Viruses are unable to heal themselves; the protein capsule can only survive outdoors for up to a week. They must therefore be sufficiently "virulent" to infect enough other cells to compensate for their losses.
Viruses employ various space-saving techniques:
overlapping genes
genes that code for one long polypeptide that is then cleaved into proteins
capsule made from few subunits
100nm
The capsule proteins join up together to form
long helical structures
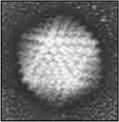
an icosahedron (of the polyhedra, it has the highest volume to surface ratio);
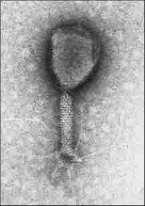
a combination of both, produced by some larger DNA viruses; the capsule holds the nucleic acid, while the helix acts as a syringe to insert it into a cell;
a flexible envelope of a lipid bilayer with the proteins embedded in it, for the larger viruses; they contain a protein to help it fuse with a cell, and another to help it bud out.
Combined (bacteriophage)Icosahedral capsule
Some viruses (viroids, plasmids, transposons...) do not code for a protein coat. They are carried from cell to cell by other viruses, bacteria etc. or are inherited down generations.
The cell itself has a number of anti-viral genes to defeat viruses:
Mutator proteins find free suspect RNA, and deaminate its C into U;
Dicer and RISC proteins cut up suspect mRNA, and use the fragments to find the complementary viral RNA;
Restriction enzymes (bacteria) find non-methylated parts of DNA, and cut it up at specific places, e.g., GAATTC;
In the worst case, interferon switches off most cellular activity to limit the damage.
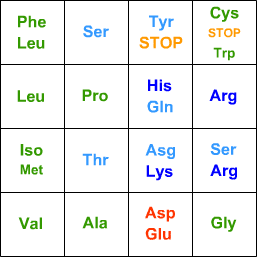
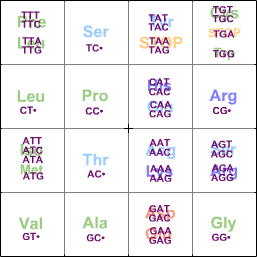 TCAGTCAGfirst basesecond base
TCAGTCAGfirst basesecond base