CSA3020
Lecture 5 - Images and Graphics
Reference: Steinmetz, R., and Nahrstedt, K. (1995). Multimedia:
Computing, Communications & Applications. Prentice Hall. Chapter 4.
Steinmetz, R. and Nahrstedt, K. (2002).
Multimedia Fundamentals: Volume 1. Prentice Hall. Chapter 4.
Introduction
Most multimedia is presented in a 2-dimensional medium, the computer
monitor. In future, immersive environments (e.g., virtual reality) will
present information in a 3-dimensional environment. We, however, will
concentrate on 2D and 3D digital images which are presented in a predominantly 2D
medium.
As with sound, an image which exists outside of a
computer environment needs to be digitized prior to being manipulated
(although graphics can be created in digital form using graphics packages
or computer-based drawing tools). There are an infinite number of natural
colours (including their shades), but, as usual, only a finite number of
them can be represented within a computer environment. The number of
colours supported by a computer monitor (through which, after all, the
graphic will primarily be viewed) is known as the colour-depth, and can be
1, 2, 4, 8, 16, or 24-bits deep (representing monochrome, 4, 16, 256,
thousands and millions of colours or grey-scale respectively). Some
high-end monitors can support a colour-depth greater than 24-bits, but usually
the extra bits are used for special effects, rather than
representing an increased range of colours.
A digital image is represented by a matrix of numeric values, each
representing a quantized intensity value. The points at which an image is
sampled are called pixels. The resolution is the number of
samples taken of the image. Within each pixel, the intensity is averaged
out to give a single value. Obviously, the higher the resolution, the
greater the number of samples, the smaller the area of each pixel, and,
consequently, the better the definition of the digital image.
Compare Figures 1 and 2 below. The image in figure 2 will resolve to a
better (although still fuzzy) representation of the original than the image in Figure 1.

Figure 1. A 2x2 grid superimposed over the original
image.

Figure 2. The same image with a 52x43 grid.
Essentially, the intensity in each pixel will be averaged through
digitization. Although both
resulting digitized images will be of poor quality, the 2x2 image will be
completely undiscernible, whereas the 52x43 image will show the basic
shape of the original image.
An image may be captured in monochrome (1-bit), grey-scale (usually 8-bit),
or colour (usually 24-bit). In each case, the intensity of each sample
taken is converted to its closest match. In the case of monochrome images,
the intensity of each pixel is thresholded at 50%. If the average intensity
of the sample is closer to black than it is to white, then it is store as
binary 1, otherwise it is stored as binary 0. In the case of grey-scale
there are (usually) 256 levels of grey. Again, the quantized value is
stored as the closest approximation to the appropriate level of grey.
However, in the case of colour images, a different technique is needed.
All colours can be represented by selective mixing of the three primary
colours red, green, and blue. There are other ways of representing colour,
but RGB is by far the most common.
Stored Image Format
A digital image is stored as a 2-dimensional array of values, where each
value represents the data associated with a pixel in the image. In the
case of bitmaps, the value is 0 or 1, which represent monochrome images.
In the case of a colour image, the value can be:
- 3 numbers representing the intensities of the red, green, and blue
components of the colour at that pixel;
- An indirect address to tables of red, green and blue intensities;
- An indirect address to a table of colour triples;
- An indirect address to any table capable of representing colour codes;
- 4 or 5 spectral samples for each colour.
The storage space required for an image is the resolution of the image
multiplied by the colour depth. For example, a 640x480 resolution image in millions of
colours requires 640x480x24 = 7,372,800 bits, or 900K. Smaller space
requirements can be obtained by compressing the image.
Computer-generated graphics
Graphics can also be created from scratch using a graphics editor, e.g.
xphigs. In this case, a graphic is specified through graphics primitives and their
attributes, rather than by a pixel matrix. This gives the advantage that
components of the image can by manipulated through the primitives (e.g.,
line, square, ellipse), whereas with a digitized image it is only possible
to manipulate the image at the pixel level.
These graphics occupy less space than a corresponding digitized image of
the same resolution and colour-depth. However, before the graphic can be
rendered on the screen it needs to be converted into a pixel matrix. Some
graphics packages also allow objects to be labeled (e.g., if you draw a
chair you can label that object as a chair). This is of particular
interest to content-based image retrieval.
Computer Image Processing
Image processing has two main areas: image synthesis and image analysis.
Image synthesis, has already been covered to an introductory level in
CSA2120, and will not be discussed further in this lecture series. Image
analysis is concerned with recovering from graphics information which is
necessary for scene analysis, e.g., automatically discerning what is in a
scene, and being able to reason about topographical relationships between
objects in a scene. Some application areas are object identification and
tracking (tracking, obviously, in an environment where there are a
sequence of images such as video), image enhancement (to improve the
quality of a digitized image), pattern detection and recognition (e.g.,
optical character recognition), and scene analysis and computer vision
(e.g., visual planning systems, and reconstructing 3D scenes from
stereoscopic images). Of obvious importance is the ability to accurately
reconstruct 3D environments for virtual realities.
Image Recognition
Figure 5.3 shows the variety of steps required to transform iconic
information into recognition information.
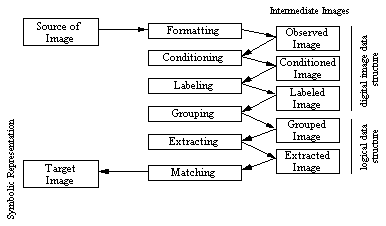
Figure 5.3. Image Recognition Steps. (From
Steinmetz, R., and Nahrstedt, K., 1995, pg.
72/Steinmetz, R. and Nahrstedt, K., 2002
, pg. 69).
Image recognition is usually performed on digital images which are
represented by a pixel matrix. The only information available to an image
recognition system is the light intensities of each pixel and the location
of a pixel in relation to its neighbours. From this information, image
recognition systems must recover information which enables objects to be
located and recognised, and, in the case of stereoscopic images, depth
information which informs us of the spatial relationship between objects in a
scene.
Image Formatting
Image Formatting means capturing an image by bringing it into a
digital form -- already covered in the section on
digitizing images.
Conditioning
In an image, there are usually features which are uninteresting, either
because they were introduced into the image during the digitization
process as noise, or because they form part of a background. An observed
image is composed of informative patterns modified by uninteresting random
variations. Conditioning suppresses, or normalizes, the uninteresting
variations in the image, effectively highlighting the interesting parts of
the image.
Labeling
Informative patterns in an image have structure. Patterns are
usually composed of adjacent pixels which share some property such that it can be
inferred that they are part of the same structure (e.g., an edge). Edge
detection techniques focus on identifying continuous adjacent pixels
which differ greatly in intensity or colour, because these are likely to
mark boundaries, between objects, or an object and the background, and
hence form an edge. After the edge detection process is complete, many edge
will have been identified. However, not all of the edges are significant.
Thesholding filters out insignificant edges. The remaining edges are
labeled. More complex labeling operations may involve identifying and
labeling shape primitives and corner finding.
Grouping
Labeling finds primitive objects, such as edges. Grouping can turn edges
into lines by determining that different edges belong to the same
spatial event. The first 3 operations represent the image as a digital
image data structure (pixel information), however, from the grouping
operation the data structure needs also to record the spatial events to
which each pixel belongs. This information is stored in a logical data
structure.
Extracting
Grouping only records the spatial event(s) to which pixels belong. Feature
extraction involves generating a list of properties for each set of pixels
in a spatial event. These may include a set's centroid, area, orientation,
spatial moments, grey tone moments, spatial-grey tone moments,
circumscribing circle, inscribing circle, etc. Additionally properties
depend on whether the group is considered a region or an arc. If it is a
region, then the number of holes might be useful. In the case of an arc,
the average curvature of the arc might be useful to know. Feature
extraction can also describe the topographical relationships between
different groups. Do they touch? Does one occlude another? Where are they
in relation to each other? etc.
Matching
Finally, once the pixels in the image have been grouped into objects and
the relationship between the different objects has been determined, the final
step is to recognise the objects in the image. Matching involves
comparing each object in the image with previously stored models and
determining the best match template matching.
Back to the index for this course.
In case of any difficulties or for further information e-mail
cstaff@cs.um.edu.mt
Date last amended: 2nd September 2002